GLiNER for Modern Named Entity Recognition

The era of one-size-fits-all large language models is over. Scaling AI applications efficiently and effectively requires careful pairing of models best suited to a given domain or task.
While some downstream tasks inevitably require a model with a broad general knowledge and skillset, this is fast becoming the exception. Agentic systems requiring multiple language models and advanced routing systems benefit greatly from using precise, specialized, low-latency models in parallel. In the era of agentic AI, model architectures should be purpose-built for downstream tasks. Using models with many billions of extra, unused parameters highly specific tasks in specialized domains no longer makes sense.
One such task is Named Entity Recognition (NER). NER is a foundational Natural Language Processing (NLP) task that identifies and classifies named entities in a given text—a capability that underpins countless applications from information extraction and question answering to knowledge graph construction and content recommendation.
In this post, we highlight an exceptionally innovative small language model optimized to perform NER: GLiNER. Released in late 2023, GLiNER represents a critical departure from the one-size-fits-all era, offering fast and performative zero-shot parallel entity extraction that is both fine-tunable and optimized for running on edge devices and consumer hardware.
How all roads lead to GLiNER for NER
Traditional NER models are limited to identifying only a fixed set of entities, making them impractical to use in niche and rapidly evolving domains. Using GPT (generative) models for NER allow for zero-shot capabilities, but require substantial compute, making them inefficient for use at scale.
Fine-tuned versions of these models, like UniNER (based on LLaMA), maintain excellent zero-shot capabilities at a fraction of the size. However, fine-tuning large generative models with decoder architectures requires significant compute resources, complex distributed training pipelines, and still leave the user with a slow, bloated model. Furthermore, generative models are trained to autoregressively predict the next token in a sequence of tokens, a slow task that primes models for language fluency, not language understanding.
The answer to efficient zero-shot NER lies in a return to the encoder architecture, which primes models for language understanding and representation, as opposed to fluency.
GLiNER is a small bidirectional model pre-trained for NER
GLiNER is a bidirectional encoder (BERT-based) model. Bidirectional models use the context both before and after a given token to build their understanding and representation of it, as opposed to unidirectional models like GPT-5 or Google Gemini, which only use the context preceding a given token to understand it.
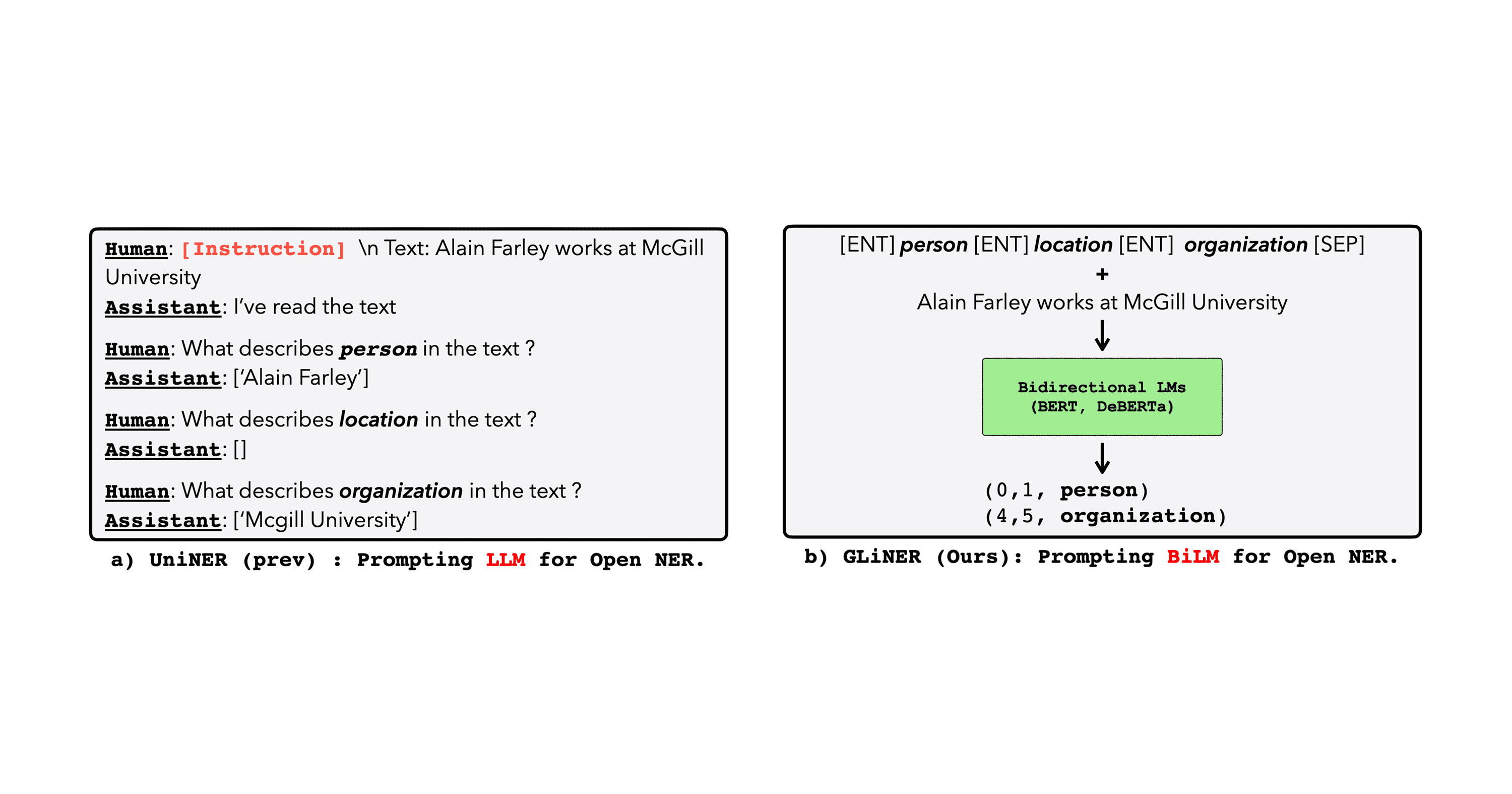
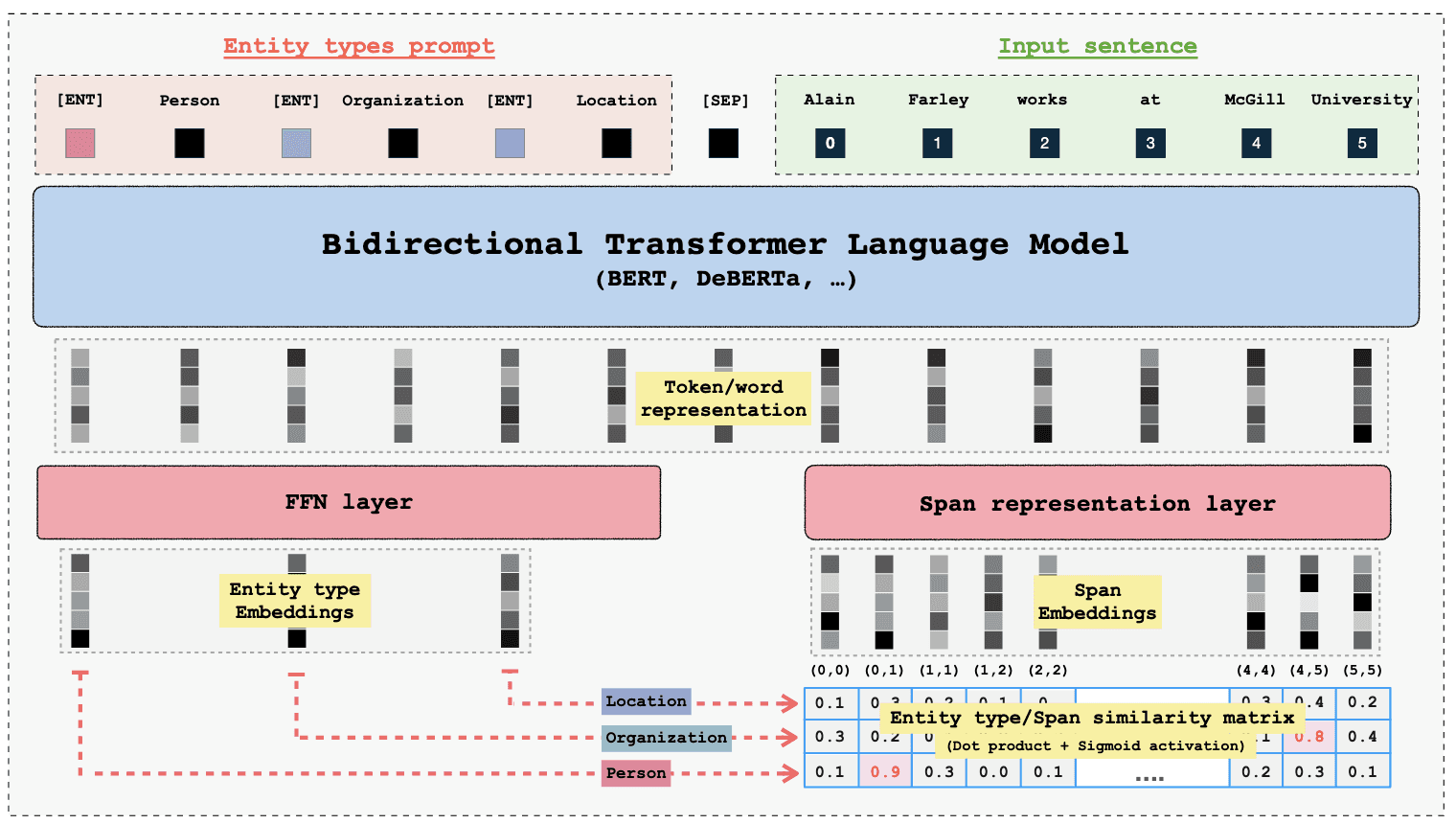
Traditional encoders like BERT or RoBERTa lack zero-shot capabilities because they are restricted to a static set of labels established during training. In contrast, GLiNER achieves zero-shot performance by framing entity extraction as a matching task rather than a generation task. Both the target labels and the input text are processed by the model, in parallel, and embedded in a shared latent space. GLiNER then calculates a similarity score between the targets and inputs—enabling it to identify entirely new entity classes without further training.
How GLiNER redefines modern NER
GLiNER represents a paradigm shift for modern Named Entity Recognition—moving away from entity extraction as a costly generative task to an efficient matching task. Moreover, GLiNER’s unique architecture gives it several competitive advantages over using unidirectional decoder models for NER tasks, including:
Size. GLiNER is only 205 million parameters in size, meaning that it can be run on edge devices and consumer hardware (no GPU necessary).
Performance. GLiNER outperforms ChatGPT and several LLMs fine-tuned for NER. This is in part due to its bidirectional architecture, which allows it to leverage context on both sides of each token, providing a deeper understanding of linguistic structure.
Zero-shot capabilities. In contrast to traditional NER models, GLiNER offers zero-shot entity recognition. It achieves this by framing entity extraction as a matching problem rather than a generation task, projecting both the input text and target entity labels into a shared latent space.
Adaptability. GLiNER’s lean compute footprint makes domain-specific fine-tuning far more accessible compared to large generative models.
Sovereignty. GLiNER’s open source license and small size means that the model and any fine-tuned variants can run comfortably and securely on device, without making any external API calls.
GLiNER's innovation lies in both its return to a bidirectional encoder architecture and its treatment of NER as a matching algorithm.
GLiNER’s size is not a compromise
Modern scaling laws dictate that model performance improves at a predictable, power-law rate relative to increases in parameters, dataset size, and training compute. GLiNER directly contradicts this by matching and even outperforming models many times larger.
Some of the most impressive results from GLiNER’s evaluation against other NER models reveal that:
GLiNER-Medium (90M) matches UniNER-13B in performance while being 140x smaller.
GLiNER-Small (50M) beats ChatGPT, Vicuna, and the 11B InstructUIE in zero-shot NER tasks.
Despite English-only training, the multilingual variant outperforms ChatGPT across most languages, particularly those using Latin scripts.
GLiNER’s task-specific architecture and efficient use of parameters allows it to defy modern scaling laws, positioning it as a viable option in replacing larger generative models for NER tasks.
Using GLiNER in production
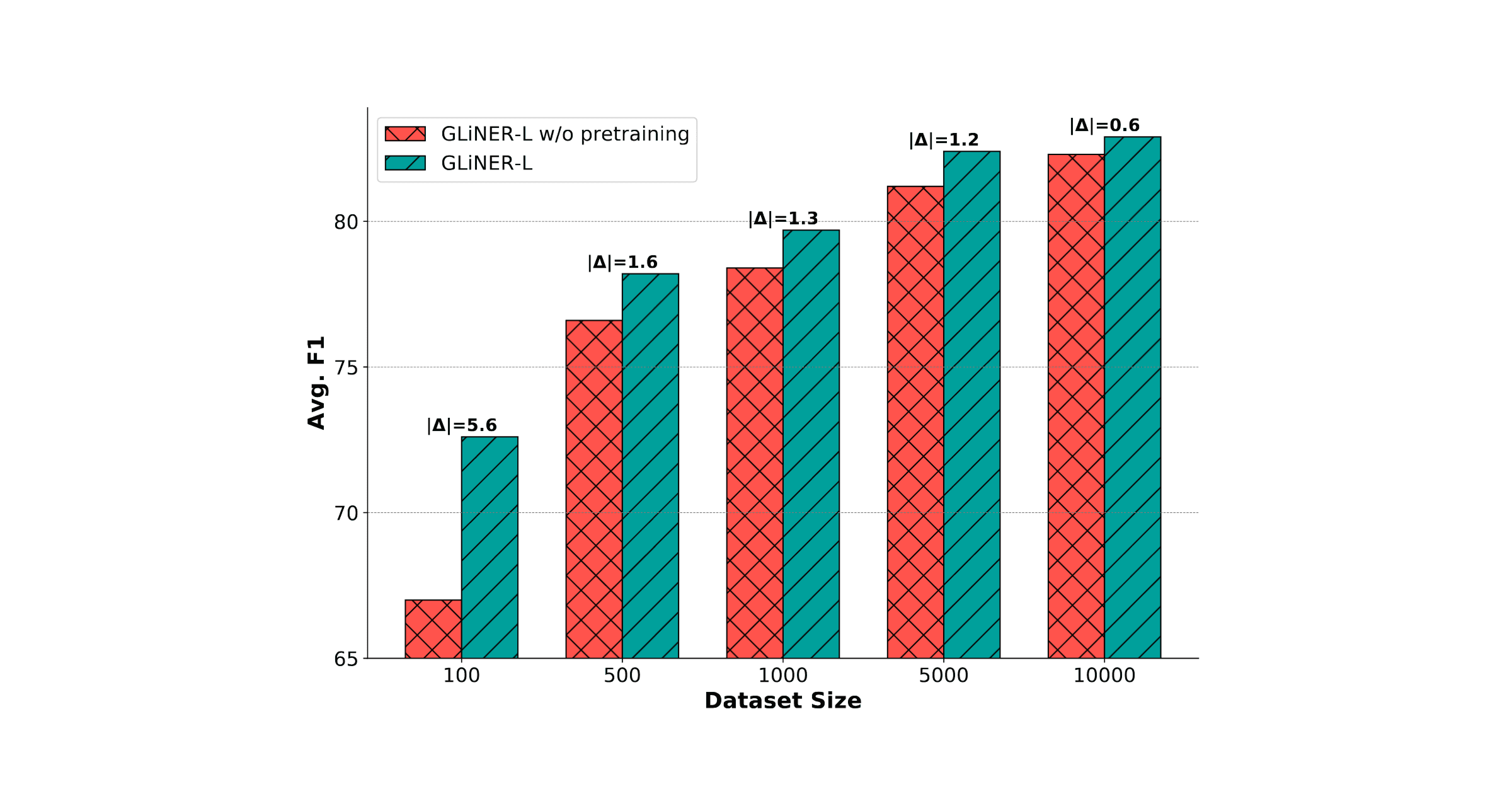
GLiNER’s size and performance make it a strong choice for use in production AI applications and agentic systems, especially in industries requiring on-premises deployment to maintain strict data privacy and compliance with regulations. And because GLiNER supports supervised fine-tuning, it is especially suitable for use cases when data is scarce and accuracy is paramount, as adding as many as 100 labeled examples can significantly increase accuracy (F1-Score) 5.6 points.Conclusion
GLiNER’s bidirectional architecture allows for efficient and performant zero-shot named entity recognition, eliminating the latency and cost bottlenecks inherent in large generative LLMs. Beyond reshaping modern NER, it also signals a broader trend in AI: a shift from using large generalist models for all tasks towards using collections of small language models fine-tuned for specific tasks. Task-specific small language models that strike the right balance between accuracy and latency are poised to be the winners.
When it comes to production workflows and applications, GLiNER is especially well suited for:
PII redaction. GLiNER can identify and extract personally identifiable information like names, contact information, and healthcare data locally, without sending information to an external API. Examples of open source GLiNER models fine-tuned for PII detection are GLiNER-PII by NVIDIA, Gretel GLiNER by Gretel AI.
Biomedical entity extraction. GLiNER works particularly well for recognizing rare biomedical entities, including diseases, chemical compounds, genes, proteins, and other entities used for drug discovery. GLiNER-BioMed is a suite of models fine-tuned on biomedical data.
Automated legal review. GLiNER can extract clauses, laws, and legal parties from confidential legal data.
Financial data extraction. GLiNER can be used to extract information for financial modeling from reports and filings.
Conclusion
GLiNER’s bidirectional architecture allows for efficient and performant zero-shot named entity recognition, eliminating the latency and cost bottlenecks inherent in large generative LLMs. Beyond reshaping modern NER, it also signals a broader trend in AI: a shift from using large generalist models for all tasks towards using collections of small language models fine-tuned for specific tasks. Task-specific small language models that strike the right balance between accuracy and latency are poised to be the winners.
Additional resources
Want to fine-tune GLiNER on your own domain? Check out current Fastino offerings.
Sources cited
Gretel AI. (2024). gretel-gliner-bi-large-v1.0 [Large language model]. Hugging Face. https://huggingface.co/gretelai/gretel-gliner-bi-large-v1.0
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., & Amodei, D. (2020). Scaling laws for neural language models. OpenAI. https://openai.com/index/scaling-laws-for-neural-language-models/
Knowledgator. (2024). GLiNER-Biomed [Model collection]. Hugging Face. https://huggingface.co/collections/knowledgator/gliner-biomed
NVIDIA. (2024). gliner-PII [Large language model]. Hugging Face. https://huggingface.co/nvidia/gliner-PII
Zaratiana, U., Tomeh, N., Holat, P., & Charnois, T. (2023). GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer (arXiv:2311.08526). arXiv. https://arxiv.org/abs/2311.08526
Zhou, W., Zhang, S., Gu, Y., Chen, M., & Poon, H. (2023). UniversalNER: Targeted distillation from world knowledge for open-ended named entity recognition. https://universal-ner.github.io/