Product

Today, we’re launching Pioneer, the world’s first agent for fine-tuning and inferencing open source SLMs and LLMs.
With Pioneer, you can fine-tune and deploy models like Qwen, Gemma, and Llama and achieve state-of-the-art performance in minutes, with a single prompt. When deployed to Pioneer’s production inference, models are then continuously optimized against live inference data, improving automatically over time without manual intervention.
By making language model development accessible to any team, Pioneer expands who can build the agentic systems that will define the next era of AI.
Agentic systems can't scale on frontier models alone
Frontier large language models have pushed the boundaries of AI. Most production tasks, however, need only a fraction of their parameters and compute. Due to their size and generalist nature, frontier models can be less accurate for specific tasks, as well as slow and costly to scale.
Small language models (SLMs) are not only cheaper and faster, but can be more accurate when fine-tuned for a specific task. Across tasks ranging from classification and text extraction to math reasoning, code generation, and summarization, fine-tuned SLMs consistently match or exceed the accuracy of frontier models many times their size.
The most effective agentic architectures use both in tandem: LLMs for reasoning and planning, and SLMs for the high-volume, latency-sensitive tasks that require deterministic accuracy.
For these reasons, we believe that specialized small models will be the primary building blocks of production AI, and the tools to build them should be accessible to everyone.
State-of-the-art accuracy with small language models
Pioneer is the first platform to offer agentic fine-tuning of open source small language models including Qwen, Gemma, Llama, and GLiNER.
Fine-tuned SLMs are increasingly proving that model size and accuracy no longer scale together, delivering more intelligence per parameter than models many times their size and often outperforming frontier models outright.
GLiNER2 is a prime example: a 205M-parameter encoder that matches GPT-4o on NER benchmarks out of the box, inferencing in less than 100 milliseconds, running entirely on CPU. Because GLiNER2 trains in minutes rather than hours, Pioneer users can go from zero training data to a deployed, fine-tuned model in a single sitting. Models fine-tuned on Pioneer have achieved 99.3% accuracy on intent classification and F1 of 0.997 on spam detection, results that meet or exceed frontier model performance from a model over 500x smaller.
With Pioneer, any developer can achieve these results without machine learning expertise, writing a single line of code, or managing any training infrastructure.
Streamlining a slow, iterative workflow
Fine-tuning a language model today takes a dedicated team, dozens of decisions, and a lot of experimentation to get right. Defining class labels, curating balanced datasets, choosing techniques, and tuning hyperparameters all require trial and error, and the model has to be retrained between every attempt.
Pioneer handles that iteration loop for you. Give it a simple task description and it fine-tunes a model end to end, freeing your team to focus on the parts that actually need human judgment. The agent has two modes: Agent and Research.
Fine-tune models in minutes with Agent Mode
In a simple dialogue format, Pioneer’s Agent Mode allows users to execute all processes in the model fine-tuning life cycle, including:
Synthetic data generation
Hyperparameter selection
Model evaluation
Deployment to production
Downloading and saving model weights
Agent Mode allows the user to make iterative changes to datasets, class labels, and hyper parameters and even compare different base models in a chat-like format, without having to touch a single line of code.
It also allows users to fine-tune production-ready SLMs quickly, in a matter of minutes. In Agent Mode, users can generate an entire synthetic training dataset, fine-tune any open source model, and evaluate its performance against frontier models in as little as 10 minutes. This means users can replace an expensive LLM API call with a fast, specialized, and performant small model in record time.
For a list of supported models see our documentation.
End-to-end autonomous fine-tuning in Research Mode
Research Mode is Pioneer's fully autonomous fine-tuning agent with web browsing access. Given only a natural-language task description, it handles the entire pipeline from dataset discovery through training and evaluation, running multiple experiments in parallel and selecting the best configurations and settings resulting in the best model. In Research Mode, Pioneer can:
Automatically find and curate training data, including supplementing with synthetically generated data
Run multiple training experiments in parallel to find the best approach, settings, and configurations
Automatically detect and recover from bad training runs
Iteratively improve the model by diagnosing failure patterns and adjusting strategy accordingly
Research mode is best used when you want to maximize model quality on a specific task and are willing to let the agent run for several hours to systematically explore the best possible training configuration.
Model quality that scales with usage
Production inference data can change quickly over time, causing a degradation in model quality. However, once models are deployed to production, they are challenging to update, requiring a time-consuming cycle of failure analysis, data curation, retraining, and validation.
Pioneer addresses this by offering native adaptive inference for all models deployed on our platform. We define adaptive inference as the process of using production inference data, including LLM-as-judge and human verdicts on model outputs, to continuously and autonomously retrain and improve deployed models.
Pioneer's agent continuously monitors deployed models through their inference traces, identifies failure patterns, and automatically trains improved checkpoints with targeted corrections, all with built-in safeguards against overfitting and regression. This means that when deployed with Pioneer, models improve over time without any human intervention. The era of ‘deploy and forget’ has arrived.
We believe adaptive inference will soon be a standard feature in model serving, but we’re the first to offer it.
Benchmarks
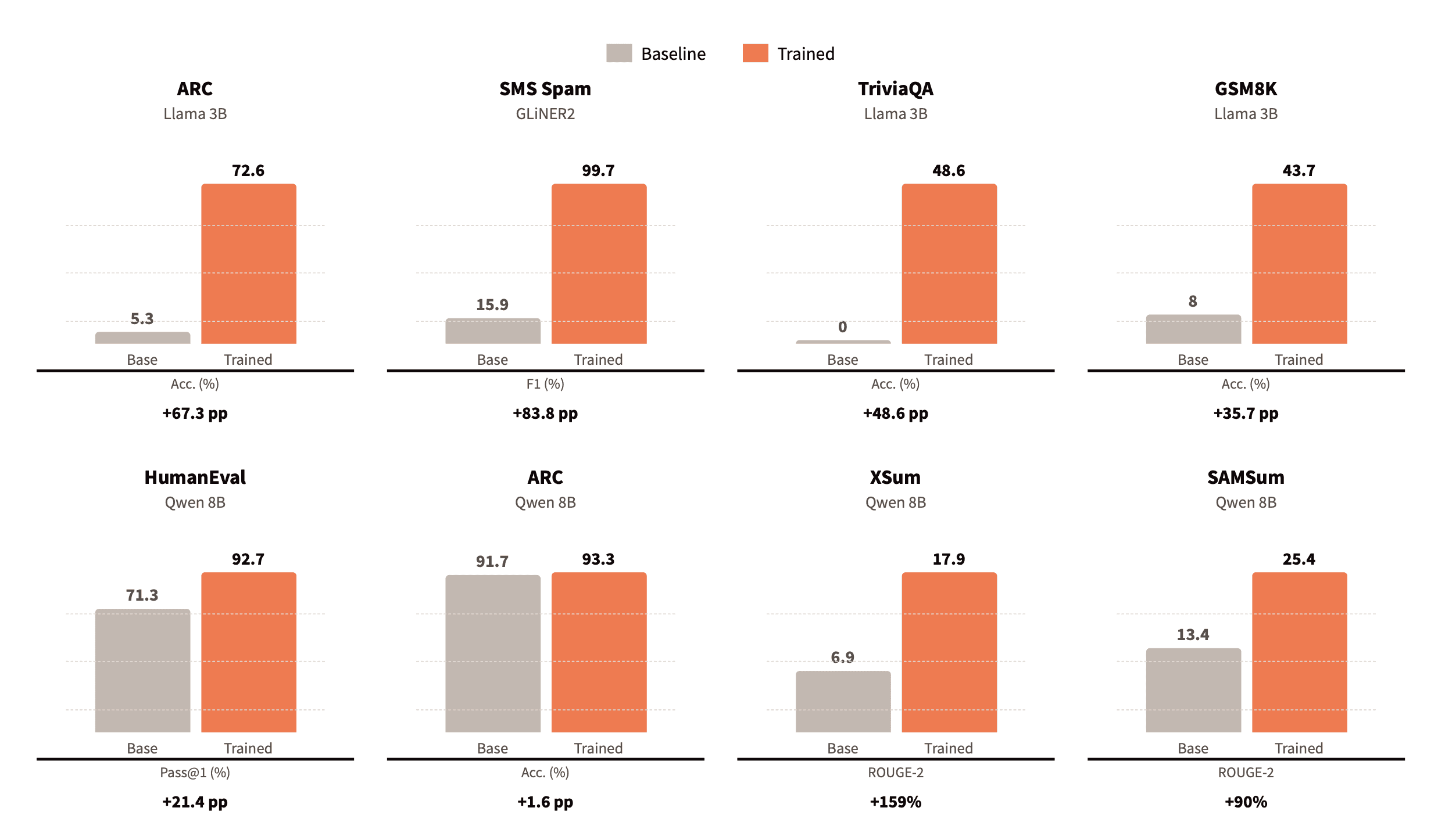
We conducted a rigorous evaluation of Pioneer's fine-tuning agents across eight benchmarks spanning reasoning, math, code generation, summarization, and classification.
In Research Mode, the autonomous agent achieved improvements of up to +84 percentage points over base models, with end-to-end runs completing in 4–12 hours at a cost of $13–55 — a fraction of the time and cost a senior machine learning engineer would spend on the same workflow.
For adaptive inference, we evaluated across seven scenarios with accumulating noise designed to simulate real-world deployment drift. Pioneer maintained monotonic improvement across all scenarios while naive retraining degraded, with final performance gaps of up to 43 percentage points.
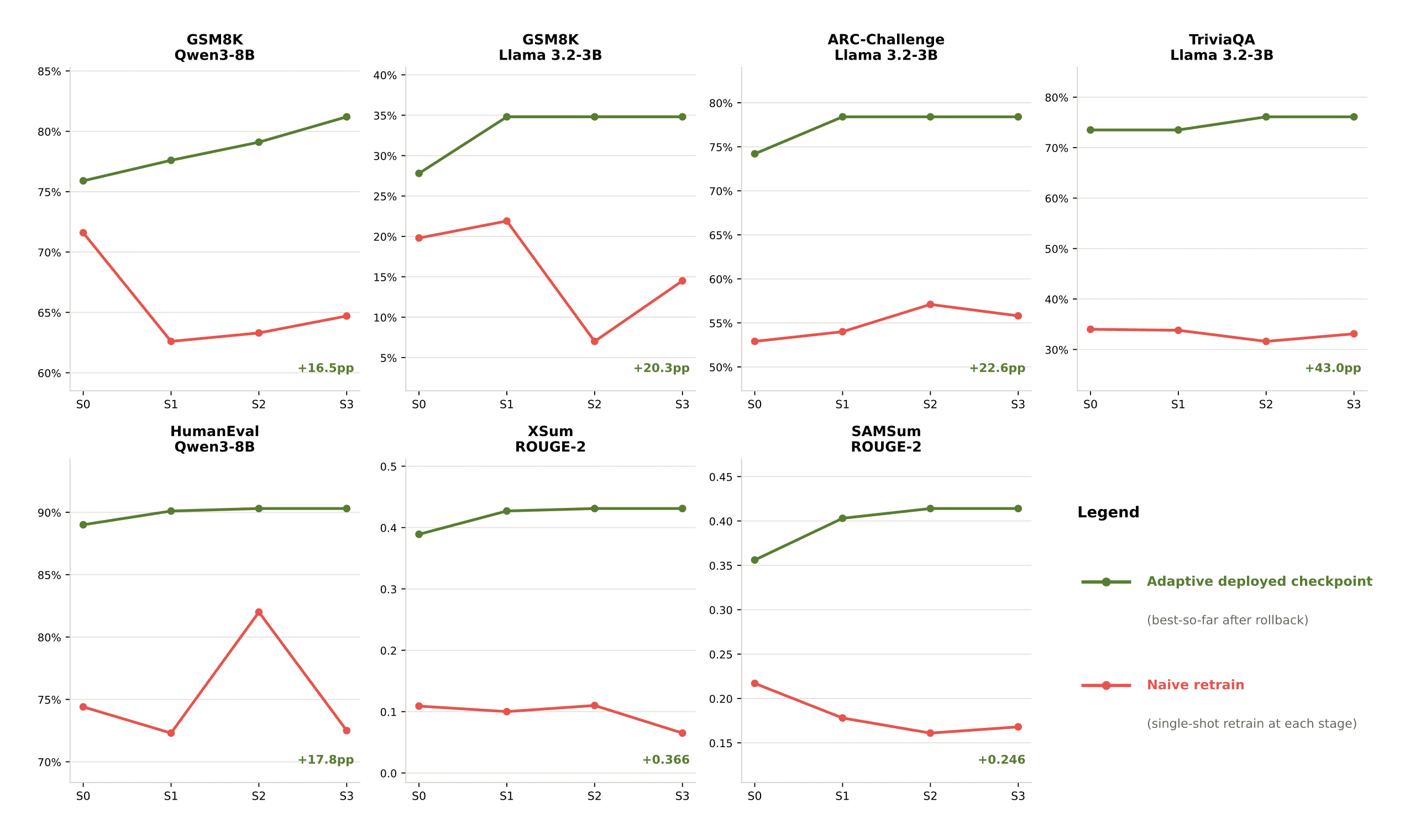
To support this work, we introduce AdaptFT-Bench, a new benchmark for evaluating autonomous model improvement under realistic production conditions. We will release a detailed technical report with full methodology and results in an upcoming blog post.
What’s next
We will be releasing a series of open source models fine-tuned with Pioneer for high-volume agentic tasks where small models can match or exceed frontier model performance.
Specialized small language models are going to be key to scaling agentic AI, and Pioneer puts that future in reach of anyone who can write a prompt.
Try Pioneer today.

Fastino Inc. (“Fastino”) develops specialized AI models and provides APIs designed to support structured data extraction, classification, reasoning, and production AI workflows. Fastino is a technology company and does not provide legal, financial, compliance, or advisory services.
Any outputs, predictions, classifications, or decisions generated through Fastino models are based on the configuration, data, and implementation provided by the customer. Fastino does not control, verify, or guarantee the accuracy, completeness, or suitability of model outputs for any specific purpose. By using this website or Fastino’s models and services, you acknowledge that all content and outputs are provided for informational and operational purposes only and agree to our Terms of Use and Privacy Policy.
2026 Fastino Inc.
All rights reserved